
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 파이썬
- HTML
- API플랫폼
- Sheety
- HTTP
- 오류
- 게임
- 유데미
- Game
- 최저가
- udemy
- 부트스트랩
- 상태코드
- 프로그램
- 계산기
- 프로젝트
- Tequila
- Endpoint
- 파싱
- API
- 쉬티
- class
- ndarray
- twilio
- SMTP
- 웹페이지
- 웹크롤링
- phython
- Python
- Pygame
- Today
- Total
데이터 분석가
쇼핑몰 데이터 분석 시각화 프로젝트 본문
안녕하세요 !

이번 시간에는 제가 기존에 진행 했었던 프로젝트를 가지고 다시 한번 분석하고 복습하는 시간을
갖도록 하겠습니다 !
***해당 자료들은 현업에서 사용하는 자료 중의 일부이므로 해당 자료에 마스킹 혹은 숫자를
임의로 수정 작업을 거쳤습니다.
먼저 해당 데이터들은 최근 5년 간의 판매 실적에 관한 자료로 무려 21만 건의 주문 정보로
데이터 분석부터 통계적 가설검정, 시각화까지 모두 진행해 나름대로 결론을 내보겠습니다

1. 데이터 탐색
2. 데이터 전처리
3. 데이터 분석
4. 모델 평가
5. 시각화
순으로 진행해 보겠습니다.
import pandas as pd # 데이터 조작과 분석을 위한 패키지
import numpy as np # 다차원 배열과 수학적 연산을 위한 패키지
import seaborn as sns # 데이터 시각화를 위한 패키지
from scipy import stats # 통계 관련 함수와 확률 분포를 다루는 패키지
from sklearn.datasets import load_iris # 붓꽃(iris) 데이터셋을 로드하는 함수
from sklearn.preprocessing import MinMaxScaler # 데이터의 스케일을 조정하는 변환기
import matplotlib.pyplot as plt # 그래프를 그리는 패키지
from scipy.stats import norm # 정규 분포의 확률 밀도 함수를 계산하는 함수
import math # 수학적인 연산을 위한 모듈일단 필요한 라이브러리를 가져오고
df = pd.read_excel("파일.xlsx")
df각자의 경로에서 파일을 불러오고 일단 형태를 봐줍시다 !
데이터를 보는데 제품에 대한 할부기간이 있어요 ! 할부 개월이 얼마나 다양한지 확인하고 싶습니다
df['할부기간'].unique()
array([nan, '12개월', '1개월', '24개월', '6개월', '18개월'], dtype=object)다음과 같이 6개의 종류가 있네요 !
그리고 df를 보니 결측값(누락된 값)이 보이네요 !
df.fillna(0, inplace = True)바로 0으로 채워서 데이터 완전성을 유지시켜 줍니다 !
df.drop_duplicates(inplace = True)중복된 행도 제거해줍시다 !
df.dtypes
--결과--
주문번호 int64
업체명 object
상품명 object
제조사 object
주문수량 int64
판매금액 int64
결제방법 object
주문일자 datetime64[ns]
처리상태 object
초도상품 object
제작문구 내역 object
할부기간 object
dtype: object타입 확인 결과는 다음과 같아요 !
자 이제 df(데이터 프레임) 구성에서 NumPy 라이브러리 활용을 통한 수치 계산을 위해np(넘파이 배열)로 변경해줍시다 !
넘파이 배열로 바꾸면 데이터를 조금 더 효율적으로 처리할 수 있고, 다양한 수학적 연산 통계 작업이 가능합니다!
df.columns
--결과--
Index(['주문번호', '업체명', '상품명', '제조사', '주문수량', '판매금액', '결제방법', '주문일자', '처리상태',
'초도상품', '제작문구 내역', '할부기간'],
dtype='object')칼럼(열) 구성을 확인해 주고
df.drop(labels = '초도상품',axis = 1, inplace = True)초도상품은 모두 N 값이므로 필요가 없을 거 같습니다. 열 삭제.
df['판매금액'].sort_values(ascending = False)
df_pirce = pd.DataFrame(df['판매금액'].sort_values(ascending = False))
df_pirce판매금액 기준으로 내림차순하여 금액이 큰 순서대로 정렬합니다.
결과
판매금액
99985 19800000
44403 11130000
73925 9600000
74292 9600000
44962 9275000
... ...
45109 0
135172 0
252 0
250 0
50055 0
215590 rows × 1 columns2115590개의 행 중 1980만원이 1등으로 나옵니다 !

과연 누가 사갔을까요... ?!
주문번호 211123163230446
업체명 00000
상품명 [xxx xx] xx
제조사 xxxx
주문수량 50
판매금액 19800000
결제방법 정기결제
주문일자 2021-xx-xx xxx:xx:xx
처리상태 구매확정
제작문구 내역 0
할부기간 24개월
Name: 99985, dtype: object한번 확인해줍니다 !.. 해당 결과는 마스킹 한 결과이고요 원본은 저만 알고 있겠습니다!
그렇게 2번째 3번째 등등도 확인해주고 생각을 합니다. 어떤 사람들이 어떤 형태로 구매를 했는지 !
저는 처리상태, 상품명이라는 열에 집중을 하였습니다
왜냐하면 일시불이 아닌 이상 집계가 번거로울 것 같아서요 !
df['처리상태'].unique()
df['상품명'].value_counts()확인해주시고,. 월별 매출 파악으로 시계열 데이터 처리인 pd.Timestamp을 이용합니다
df['주문일자'] = df['주문일자'].apply(lambda x: pd.Timestamp(x))
# 월별 매출
list1 = []
for x in df['주문일자'].unique():
m = df['주문일자'] == x
temp = df[m]
res = temp['판매금액'].sum()
list1.append([x, res])그 다음 결과로
pd.DataFrame(list1)
--결과--
0 1
0 2019-12-13 17:03:37 5000
1 2019-12-16 10:04:50 72500
2 2019-12-16 17:33:43 72750
3 2019-12-17 14:29:52 900
4 2019-12-18 13:16:06 105000
... ... ...
148663 2022-11-08 10:35:02 9600
148664 2022-11-08 10:38:21 61900
148665 2022-11-08 10:43:15 26900
148666 2022-11-08 10:45:14 4050
148667 2022-11-08 10:49:28 161500
148668 rows × 2 columns깔끔하게 정리가 됐습니다 !
여기서 행 결과에 주목합시다
2115590행이 148668행으로 줄어들었습니다 ..
조금 살펴 보니 주문번호가 같고 동시에 결제된 물품의 경우 금액이 합산 되었습니다 !

월별 매출 집계
def extract_month(date):
return str(date.year)+str(date.month).rjust(2,'0')### 월별 매출
month_sell=df1.set_index('주문일자').groupby(extract_month).sum()['판매금액']
month_sell
month_sell.T
pd.DataFrame(month_sell) 판매금액
주문일자
201912 9350160
202001 27984260
etc...
202210 450717480
202211 183279300다음과 같이 월별 매출을 어렵지 않게 확인할 수 있었습니다 !
df_monthly_sales = pd.DataFrame(month_sell)
df_monthly_sales.columns = ['판매금액']
df_monthly_sales['주문일자'] = df_monthly_sales.index
df_monthly_sales.reset_index(drop=True, inplace=True)
df_monthly_sales다음의 결과는 35 rows x 2 colomn
판매금액 주문일자
0 9350160 201912
1 27984260 202001
2 ets ...
35 183279300 202211잘 나왔습니다 !!
df_yearly_sales = df_monthly_sales.copy()
df_yearly_sales['연도'] = df_yearly_sales['주문일자'].str[:4]
df_yearly_sales = df_yearly_sales.groupby('연도')['판매금액'].sum().reset_index()
df_yearly_sales 연도 판매금액
0 2019 xxxxx60
1 2020 xxxxx65315
2 2021 xxxxx87364
3 2022 xxxxx71720연도별도 봅시다 !
잘 나옵니다
하지만 여기서 데이터를 보다보니 할부기간 열에서 '할부'라는 것이 보이고, 처리상태 열에서 '미결재'를
확인할 수 있었어요. 그렇다면 실제 총 판매금액을 위해선 할부는 결제 직후 할부 계산이 적용되고
미결제는 판매금액에서 제외를 시켜야 할 것 같습니다

# '주문일자'를 datetime 형식으로 변환
df['주문일자'] = pd.to_datetime(df['주문일자'], format='%Y-%m-%d %H:%M:%S')
# '처리상태'가 '할부'인 데이터 필터링
installment_data = df[df['처리상태'] == '할부']
installment_data['할부기간'] = installment_data['할부기간'].astype(int)
# 할부 개월 수에 따른 판매 금액 계산
installment_data['할부금액'] = installment_data['판매금액'] / installment_data['할부기간']
# '처리상태'가 '미결제'인 데이터 제외
filtered_data = df[df['처리상태'] != '미결제']
# 월별 판매 금액 계산
monthly_sell = pd.concat([
filtered_data.groupby(pd.Grouper(key='주문일자', freq='M'))['판매금액'].sum(),
installment_data.groupby(pd.Grouper(key='주문일자', freq='M'))['할부금액'].sum()
], axis=1, keys=['판매금액', '할부금액']).fillna(0)
# 결과 출력
print(monthly_sell)다음과 같이 할부가 적용되고 미결제는 제외시키고 다시 계산을 했습니다!
# 월별 판매 금액 계산
monthly_sell = monthly_sell.groupby(pd.Grouper(freq='M')).sum()
# 결과 출력
print("=== 월별 판매 금액 ===")
print(monthly_sell)
# 연도별 판매 금액 계산
yearly_sell = monthly_sell.groupby(monthly_sell.index.year).sum()
# 결과 출력
print("=== 연도별 판매 금액 ===")
print(yearly_sell)결과는
=== 월별 판매 금액 ===
판매금액 할부금액
주문일자
2019-12-31 xxxx160 0.0
2020-01-31 xxxxx540 0.0
2020-02-29 xxxx4720 0.0
etc...
2021-09-30 327964015 0.0
...
2019 5xxxx60 0.0
2020 xxxx497035 0.0
2021 xxxxx57013 0.0
2022 xxxxx52420 0.0결과가 잘 나왔습니다 ! 이게 진짜 판매금액일 것 같습니다!

그리고 저는 월별 가장 판매금액이 높은 구매업체를 알아보고,
이를 바탕으로 월별 가장 판매금액이 높은 물품을 알아보겠습니다
# 월별 판매금액을 기준으로 데이터 그룹화
monthly_sales = df.groupby(pd.Grouper(key='주문일자', freq='M'))
# 각 그룹에서 판매금액이 가장 높은 업체명 추출
top_company_by_month = monthly_sales.apply(lambda x: x.loc[x['판매금액'].idxmax(), '업체명'])
# 결과 출력
result = pd.DataFrame({'월별 판매금액 최고 업체명': top_company_by_month})
print(result)계산 결과 2021 8월부터 ~ 현재까지 어떤 특정한 업체에서 1위를 차지하고 있네요 !

# 월별 판매금액을 기준으로 데이터 그룹화
monthly_sales = df.groupby(pd.Grouper(key='주문일자', freq='M'))
# 각 그룹에서 판매금액이 가장 높은 업체 추출
top_company_by_month = monthly_sales.apply(lambda x: x.loc[x['판매금액'].idxmax(), '업체명'])
# 각 업체별로 판매금액이 가장 높은 상품 추출
top_product_by_company = top_company_by_month.apply(lambda x: df.loc[df['업체명'] == x, '상품명'].iloc[0])
# 결과 출력
result = pd.DataFrame({'월별 판매금액 최고 업체명': top_company_by_month, '판매금액이 가장 높은 상품': top_product_by_company})
print(result)판매금액이 가장 높은 상품 역시 2021년 8월부터 ~ 현재까지 변하지 않고 있습니다 !
이를 바탕으로 알 수 있는 점은, 2019년 초반에는 판매금액이 적고 매달 판매금액이 높은 상품명이 계속 바뀌는 것을 볼 수
있었는데요, 꾸준히 월별 판매금액이 높아짐에 따라 2021년 9월을 기점으로 안정적으로 자리를 잡았음을 알 수 있네요
from scipy.stats import pearsonr
# 판매금액이 가장 높은 상품 추출
top_product = df.loc[df['판매금액'].idxmax(), '상품명']
# 판매금액과 상품명 간의 상관계수와 p-value 계산
correlation, p_value = pearsonr(df['판매금액'], df['상품명'] == top_product)
# 결과 출력
print("판매금액과 가장 높은 상품 '{}' 간의 상관계수: {:.4f}".format(top_product, correlation))
print("p-value: {:.4f}".format(p_value))결과
판매금액과 가장 높은 상품 '[xxxxx] xxxxx' 간의 상관계수: 0.22080.5보다 작으므로 통계적으로 유의하며, 해당 변수 간의 약한 양의 상관 관계를 가지고 있네요 !

from sklearn.preprocessing import StandardScaler # 데이터의 표준화를 위한 스케일러
from sklearn.decomposition import PCA # 주성분 분석을 위한 PCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis # 선형 판별 분석을 위한 LDA
from sklearn.datasets import load_iris # Iris 데이터셋 로드
import pandas as pd # 데이터 처리를 위한 판다스
from sklearn.preprocessing import MinMaxScaler # 데이터의 정규화를 위한 스케일러자 이제 차원 축소해 봅시다
columns_to_scale = []
numeric_columns = [col for col in df.columns if df[col].dtype in [np.float64, np.int64]]
scaler = MinMaxScaler()
scaler.fit(df[numeric_columns])
scaled_data = scaler.transform(df_numeric) # 스케일링된 데이터 얻기
scaled_df = pd.DataFrame(scaled_data, columns=df_numeric.columns) # 스케일링된 데이터프레임 생성
print(scaled_df)결과
주문번호 주문수량 판매금액
0 0.000000 0.0005 0.000253
1 0.000098 0.0005 0.000253
2 0.000098 0.0015 0.003409
3 0.000100 0.0010 0.001515
4 0.000100 0.0005 0.000038
... ... ... ...
218596 1.000000 0.0005 0.001768
218597 1.000000 0.0005 0.001359
218598 1.000000 0.0005 0.001359
218599 1.000000 0.0005 0.000205
218600 1.000000 0.0085 0.008157
[218601 rows x 3 columns]MinMaxScaler는 최솟값을 0 최댓값을 1로 설정하는 데이터 변환입니다 !
시각화
import matplotlib.pyplot as plt
# 주문일자를 날짜형식으로 변환
df['주문일자'] = pd.to_datetime(df['주문일자'])
# 주문일자 별 주문금액 line plot
plt.figure(figsize=(12, 6))
plt.plot(df['주문일자'], df['판매금액'])
plt.xlabel('주문일자')
plt.ylabel('판매금액')
plt.title('주문일자 별 판매금액 변화')
plt.xticks(rotation=45)
plt.show()1. Lineplot

2번 3번 시각화는 월별 , 년도별 ,판매금액 세 가지 변수 를 이용해서 시각화 해보겠습니다
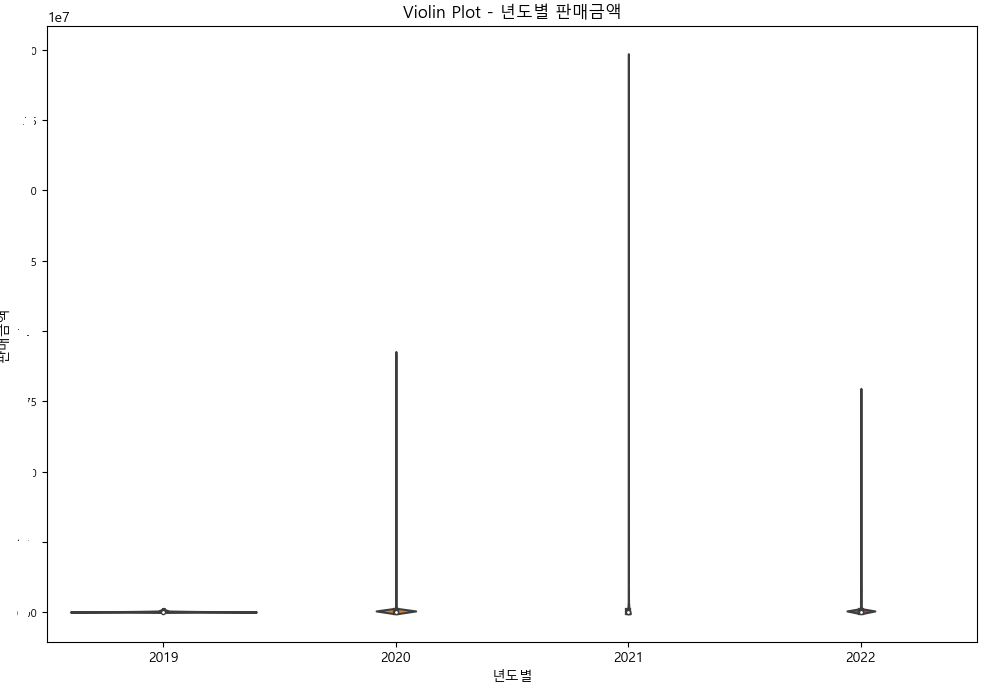
2.Violin plot
# '주문일자'를 datetime 형식으로 변환
df['주문일자'] = pd.to_datetime(df['주문일자'], format='%Y-%m-%d %H:%M:%S')
# '월별'과 '년도별' 열 추가
df['월별'] = df['주문일자'].dt.to_period('M')
df['년도별'] = df['주문일자'].dt.year
# 결제방법, 월별 판매금액, 년도별 판매금액 데이터 전처리
df_violin = df.groupby(['결제방법', '월별', '년도별']).sum()['판매금액'].reset_index()
# 결과 출력
print(df_violin)# 결제방법, 월별 판매금액, 년도별 판매금액 데이터 전처리
df_violin = df.groupby(['결제방법', '월별', '년도별']).sum()['판매금액'].reset_index()# 월별 판매금액의 Violin Plot
plt.figure(figsize=(12, 8))
sns.violinplot(x='월별', y='판매금액', data=df)
plt.title('Violin Plot - 월별 판매금액')
plt.xlabel('월별')
plt.ylabel('판매금액')
plt.xticks(rotation=60, fontsize=8)
plt.yticks(fontsize=8)
plt.show()
# 년도별 판매금액의 Violin Plot
plt.figure(figsize=(12, 8))
sns.violinplot(x='년도별', y='판매금액', data=df)
plt.title('Violin Plot - 년도별 판매금액')
plt.xlabel('년도별')
plt.ylabel('판매금액')
plt.yticks(fontsize=8)
plt.show()
다음과 같습니다.
3. heatmap 시각화
import seaborn as sns
import matplotlib.pyplot as plt
# 월별, 년도별, 판매금액 데이터 전처리
df_heatmap = df.groupby(['월별', '년도별']).sum()['판매금액'].reset_index()
# Pivot table 생성
pivot_table = df_heatmap.pivot('월별', '년도별', '판매금액')
# Heatmap 그리기
plt.figure(figsize=(12, 8))
sns.heatmap(pivot_table, cmap='YlGnBu', annot=True, fmt=',')
plt.title('Monthly and Yearly Sales Heatmap')
plt.xlabel('Year')
plt.ylabel('Month')
plt.show()
3번 heatmap이 가장 깔끔하고 보기 좋은거 같습니다 !

마지막으로 월별 판매금액과 월별 가장 판매금액이 높은 상품 간의 정규성 확인 및 상관성 분석
Shapiro-Wilk 검정으로 정규성 확인
Q-Q Plot 분포 이상치 극단값 확인.
# 월별 가장 판매금액이 높은 상품 데이터 생성
highest_sales_product = df.groupby('월별')['판매금액'].idxmax()
highest_sales_product = df.loc[highest_sales_product, ['월별', '상품명', '판매금액']]
# 월별 가장 판매금액이 높은 상품 판매금액 데이터 추출
highest_sales_product_sales = highest_sales_product['판매금액']
# Shapiro-Wilk 검정 수행
_, p_value = stats.shapiro(highest_sales_product_sales)
# QQ Plot 그리기
plt.figure(figsize=(8, 6))
stats.probplot(highest_sales_product_sales, dist='norm', plot=plt)
plt.title('Q-Q Plot - 월별 가장 판매금액이 높은 상품 판매금액')
plt.xlabel('Theoretical Quantiles')
plt.ylabel('Ordered Values')
plt.show()
# Shapiro-Wilk 검정 결과 출력
print("Shapiro-Wilk test p-value:", p_value)
Shapiro-Wilk test p-value: 3.9473183278460056e-05먼저, QQ 플롯은 이상값 유무와 정규성 확인을 위한 함수인데, 직선에 점들이 가까울수록 정규성을 갖습니다
즉, 월별 판매금액이 가장 높은 상품과 월별 판매금액은 정규성을 가진다고 볼 수 있습니다.
하지만, Shapiro 검정에 따르면 p값이 3.94로 0.5보다 훨씬 크므로, 정규성을 가진다고 볼 수 없네요.
이상으로 시각화 분석이었습니다 !

'다양한 자료 정리' 카테고리의 다른 글
| Bootstrap을 이용한 HTML 사이트 만들기 (0) | 2023.04.24 |
|---|---|
| Google SMTP 프로토콜 설정 (0) | 2023.04.20 |
| 유용한 사이트 정리 (0) | 2023.04.18 |
| 테킬라 Tequila 항공권 정보 제공 API 플랫폼 (0) | 2023.04.09 |
| 트윌리오 Twilio SMS 문자 보내기 (0) | 2023.04.08 |

